So you decided to create Always On Availability Groups with Multi-Subnet Failover Cluster which gives you the opportunity to failover across different data centers that you have in different regions or continents. Lately, we created this scenario for our monitoring tool with 2 different Subnets. Along the way, we have faced some issues and fixed them. I prepared this post to give you a quick summary about our experiences.
First of all, Multi Subnet Failover Cluster needs to be created and configured by Windows or Domain Admins.
Command:
Install-WindowsFeature -Name Failover-Clustering -IncludeManagementTools
New-Cluster -Name MS-SQL-FC -Node SCOMDB1, SCOMDB2 -StaticAddress x.x.x.x, y.y.y.y
In this example:
Cluster Name Object(CNO) : MS-SQL-FC
Nodes: SCOMDB1(Primary),SCOMDB2(Secondary)
After Multi-Subnet Failover Cluster ready, Always On feature needs to be enabled on both SQL Services. After this feature enabled, a service restart is required. If you enable this feature before cluster is fully operational and ready you will get an error when you try to create AG such as:
|
Msg 35220, Level 16, State 1, Line 92
Could not process the operation. Always On Availability Groups replica manager is waiting for the host computer to start a Windows Server Failover Clustering (WSFC) cluster and join it. Either the local computer is not a cluster node, or the local cluster node is not online. If the computer is a cluster node, wait for it to join the cluster. If the computer is not a cluster node, add the computer to a WSFC cluster. Then, retry the operation.
Disconnecting connection from HOSTNAME…
|
Now, we can continue to Always On Availability Group setup. The tricky part here is not using New Availability Group Wizard but using TSQL! There are 3 reasons:
1- You can not create an empty Availability Group with Wizard. Most of the time you need to setup Availability Group prior to application setup. In that case, people (even some DBAs with 15 years background) create dummy databases just to create AG, that breakes my heart in two. You can create empty AG with TSQL.
2- When you create an Availability Group with Wizard and add a database with backup & restore seeding method, the user who launced the Wizard will be the owner of :
- Endpoint
- Availability Group
- Database
Guess what is going to happen when that individual leaves the company? Thus use T-SQL Scripts and specify an account with EXECUTE AS LOGIN command! It could be sa or a dedicated svc account for this purpose. In my example I will be using sa account.
3- It’s fun, fast and more secure.
Below script should be executed on both SCOMDB1 and SCOMDB2 to create Endpoint for AG communication and Extended Events to monitor AG:
USE [master]
GO
EXECUTE AS LOGIN=’sa’
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATA_MIRRORING (ROLE = ALL, ENCRYPTION = REQUIRED ALGORITHM AES)
GO
IF (SELECT state FROM sys.endpoints WHERE name = N’Hadr_endpoint’) <> 0
BEGIN
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED
END
USE [master]
GO
EXECUTE AS LOGIN=’sa’
GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [sa]
GO
IF EXISTS(SELECT * FROM sys.server_event_sessions WHERE name=’AlwaysOn_health’)
BEGIN
ALTER EVENT SESSION [AlwaysOn_health] ON SERVER WITH (STARTUP_STATE=ON);
END
IF NOT EXISTS(SELECT * FROM sys.dm_xe_sessions WHERE name=’AlwaysOn_health’)
BEGIN
ALTER EVENT SESSION [AlwaysOn_health] ON SERVER STATE=START;
END
GO
Create Always On Availability Group on SCOMDB1:(Make sure to edit Failover Mode, Availability Mode and other options according to your business needs)
EXECUTE AS LOGIN=’sa’
CREATE AVAILABILITY GROUP [SCOMBAG]
WITH (AUTOMATED_BACKUP_PREFERENCE = PRIMARY,
BASIC,
DB_FAILOVER = ON,
DTC_SUPPORT = NONE)
FOR
REPLICA ON N’SCOMDB1′ WITH (ENDPOINT_URL = N’TCP://SCOMDB1.FQDN:5022′, FAILOVER_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO)),
N’SCOMDB2′ WITH (ENDPOINT_URL = N’TCP://SCOMDB1.FQDN:5022′, FAILOVER_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO));
Create Always On Listener on SCOMDB1
EXECUTE AS LOGIN=’sa’
ALTER AVAILABILITY GROUP [SCOMBAG]
ADD LISTENER N’SCOMBAG-L’ (
WITH IP
((N’10.x.x.z’, N’255.255.255.0′),
(N’10.y.y.z’, N’255.255.255.0′)
)
, PORT=1433);
Join Secondary Host to AG
EXECUTE AS LOGIN=’sa’
ALTER AVAILABILITY GROUP [SCOMBAG] JOIN;
EXECUTE AS LOGIN=’sa’
ALTER AVAILABILITY GROUP [SCOMBAG] GRANT CREATE ANY DATABASE;
Now, You can create your database(s) and add them to Availability Group. There are two prerequisites for adding a database to Availability Group:
- Database should be in FULL recovery mode
- At least one full backup should be performed
After a database meets these requirements, you can prepare database on secondary with backup & restore method by executing below script in SQLCMD mode
–Prepare database on secondary with backup & restore method
:Connect SCOMDB1
EXECUTE AS LOGIN = ‘sa’;
BACKUP DATABASE [DBNAME] TO DISK = N’DBNAME_AG.bak’
:Connect SCOMDB2
EXECUTE AS LOGIN = ‘sa’;
RESTORE DATABASE [DBNAME] FROM DISK = N’DBNAME_AG.bak’ WITH NORECOVERY
:Connect SCOMDB1
EXECUTE AS LOGIN = ‘sa’;
BACKUP LOG [DBNAME] TO DISK = N’DBNAME_AG_log.bak’
:Connect SCOMDB2
EXECUTE AS LOGIN = ‘sa’;
RESTORE LOG [DBNAME] FROM DISK = N’DBNAME_AG_log.bak’ WITH NORECOVERY
Now, Database is ready and you can add it to Availability Group
–CONNECT TO PRIMARY
:Connect SCOMDB1
EXECUTE AS LOGIN = ‘sa’;
ALTER AVAILABILITY GROUP [SCOMBAG] ADD DATABASE OperationsManager;
–CONNECT TO SECONDARY
:Connect SCOMDB2
EXECUTE AS LOGIN = ‘sa’;
ALTER DATABASE [OperationsManager] SET HADR AVAILABILITY GROUP = [SCOMBAG];
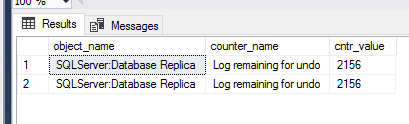
–Check the dashboard.
The thing about multiple DNS Records
When we create the cluster, CNO creates DNS records under its name on DNS server for each subnet on the failover cluster such as:
MS-SQL-FC 10.x.x.x
MS-SQL-FC 10.y.y.y
When we create Always On Listener from SQL Server,RegisterAllProvidersIP setting will be set to 1 automatically. As a result, Listener Cluster Resource creates DNS records for each subnet ip it has been assigned such as:
SCOMBAG-L 10.x.x.z
SCOMBAG-L 10.y.y.z
This is an intended behaviour by design. If you add “MultiSubnetFailover=true” clause into connection string and your connector supports this feature(you can check here) database connector gets two DNS records from DNS server and then tries to connect both IP addresses in parallel (theoratically) and connects to right one. Thus, downtime will be minimized in case of a failover.
However, there may be such cases like older database clients doesn’t support MultiSubnetFailover option or your application doesn’t support this feature like our monitoring tool. Then, clients will get timeout errors for %50 percent of their requests inevitably since half of the connections would use wrong DNS record.
To solve this, you have to set RegisterAllProvidersIP to 0, then only the online subnet’s IP will be registered with DNS. You also need to set HostRecordsTTL parameter to reduce downtime. By default it is 1200 seconds, which means that every 20 minutes Local DNS Cache will be updated and application server will learn online IP. Common best practice is setting it to 600 so Local DNS cache will be updated every 5 minutes. Thus, in case of a failover, downtime will be only 5 minutes. We set it to 60 seconds in our case. You can set this parameters for Cluster Name and Listener Network Name through Powershell as:
Get-ClusterResource “Cluster Name“ | Set-ClusterParameter -Name HostRecordTTL -Value 120
Get-ClusterResource “Cluster Name” | Set-ClusterParameter -Name RegisterAllProvidersIP -Value 0
Get-ClusterResource “SCOMBAG-L” | Set-ClusterParameter -Name HostRecordTTL -Value 120
Get-ClusterResource “SCOMBAG-L” | Set-ClusterParameter -Name RegisterAllProvidersIP -Value 0
The listener name resource has to be taken offline and back online for the above changes to take effect. If you do these parameter settings in setup phase, then you are a wise man. If you find out after you installed the environment and clients started to complain about timeout errors, then taking Listener name resource offline will also take the availability group offline since it is dependent on Listener name resource. To prevent this, you should remove the dependency with Powershell or by the Windows Failover Cluster Manager utility.
Windows Failover Cluster Manager:
- Open Properties of Availability Group Role
- Click Dependencies Tab and Delete Listener Name Resource
Powershell:
Remove-ClusterResourceDependency -Resource SCOMBAG -Provider SCOMBAG-L
Now you have to take listener name resource offline and back online.
Stop-ClusterResource SCOMBAG-L
Start-ClusterResource SCOMBAG-L
Force DNS Update
Get-ClusterResource SCOMBAG-L | Update-ClusterNetworkNameResource
Re-add dependency
Windows Failover Cluster Manager:
- Open Properties of Availability Group Role
- Click Dependencies Tab and Click Resource dropbox
- Select Listener Name Resource and Apply
Powershell:
Add-ClusterResourceDependency -Resource SCOMBAG -Provider SCOMBAG-L
Reconfigure Listener Port configuration from SSMS:
ALTER AVAILABILITY GROUP [SCOMBAG] MODIFY LISTENER ‘SCOMBAG-L’ (PORT=1433);