The other day I had an interesting incident with my Always On servers. After a successful failover to other site, new secondary(old primary) database stuck in Reverting / In Recovery status for a looooong time. I wondered why, i did some research and here is what I found.
PROBLEM:
We have 2 Stand Alone Always On nodes on a Multi-Subnet Failover Cluster.
Availability Mode: Sync Commit
Failover Mode: Automatic Failover
We performed a failover from Node 1 to Node 2. Failover is finished successfully and database is online now on Node 2. However, Node 1 did not switch to “Sychronized” state. Instead, it got stuck in Reverting/In Recovery state like in below figure.
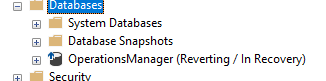
Since it is in “Reverting / In Recovery” state, applications and end-users were not able to access it on secondary.
CAUSE:
According to MS documentation for dm_hadr_database_replica_states:
3 = Reverting. Indicates the phase in the undo process when a secondary database is actively getting pages from the primary database. Caution: When a database on a secondary replica is in the REVERTING state, forcing failover to the secondary replica leaves the database in a state in which it cannot be started as a primary database. Either the database will need to reconnect as a secondary database, or you will need to apply new log records from a log backup.
It basically tells that we initiated a failover from Node 1 to Node 2 while there was running transactions on Node 1 for long time and they were interrupted by failover. Naturally Node 1 have to complete rolling back those transactions before accept new pages from primary site and become available again. During this process, secondary will be unavailable to reports, read-only routing requests, backups etc.
FIX:
Always check open and running transactions before initiating a failover! Especially the ones that produces tons of logs such as index maintenance, big chunks of DML operations and so on.If you see such activity on availability database(s), either wait them to finish or stop them.
Well, there is no fix. If you already did failover and saw database in reverting state, there is nothing you can do other than waiting for the completion of rollback operation. Undo phase should be finished and this may take long time. In my case, it took 30 minutes to rollback all transactions and complete reverting stage . Only after than secondary replica became available and switched to “Synchronized” state. There will be 3 phases of secondary database replica state during undo process:
- Synchronization State: “NOT SYNCHRONIZING” ; Database State: ONLINE
- Synchronization State: “NOT SYNCHRONIZING” ; Database State: RECOVERING
- Synchronization State: “REVERTING” ; Database State: RECOVERING
This states can be viewed by executing below query:
select DB_NAME(database_id) as DatabaseName
,synchronization_state_desc
,database_state_desc
from sys.dm_hadr_database_replica_states
where is_local=1 and is_primary_replica=0

But hey, cheer up! You can watch 3rd phase of undo process by looking at the counter :
SQLServer:Database Replica Log remaining for undo
You may monitor it via Performance Monitor tool or from system dmv. We are using Windows Core on database hosts thus I have to monitor this counter from dm_os_performance_counters as:
SELECT [object_name],
[counter_name],
[cntr_value] FROM sys.dm_os_performance_counters
WHERE [object_name] LIKE ‘%Database Replica%’
AND [counter_name] = ‘Log remaining for undo’
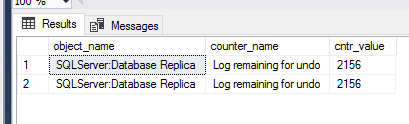
This Counter Value shows the amount of log in kilobytes remaining to complete the undo phase according to MS documentation.
When this is done, database is switching to Synchronized immediately.
To sum up, if you have long running transactions on primary site before failover occurs, it will be in reverting stage for a while. That’s why, I think it is a good practice to check running processes before initiating failover even though AlwaysOn Dashboard shows no data loss. If you ever encounter this, you may monitor the process by looking at replica states of secondary replica and watching Log remaning for undo counter.
